




Pronunciation of American English Consonants and Semivowels
Contents
2 Anatomy of speech organs
2.1 From lungs to larynx
2.2 The upper vocal tract
3 Consonants and semivowels
3.1 Phonemes and allophones
3.2 Description of consonants and semivowels
3.3 Voicing of consonants
4 The American English consonants
4.1 Stops
4.1.1 Bilabial sounds [ph], [p], [p˺], and [b]
4.1.2 Alveolar sounds [th], [t], [t˺], and [d]
4.1.3 Velar sounds [kh], [k], [k˺], and [g]
4.1.4 Glottal sound [ʔ]
4.1.5 Glottalized sound [tʔ]
4.2 Fricative sounds
4.2.1 Labio-dental sounds [f] and [v]
4.2.2 Dental sounds [∂], [∂̞] and [ɵ]
4.2.3 Alveolar sounds [s] and [z]
4.2.4 Post-alveolar sounds [ʃ] and [ʒ]
4.2.5 Glottal sound [h]
4.3 Affricate consonants
4.3.1 Consonants [ʧ] and [ʤ]
4.4 Nasal consonants
4.4.1 Stops [m], [n], and [ɳ]
4.5 Approximant Consonants
4.5.1 r-Consonants [ɹ], [ɾ], and [ɻ]
4.5.2 Lateral sounds [l] and [lɤ]
4.6 Semivowels
4.6.1 Palatal semivowel [j]
4.6.2 Velar semivowel [w]
5 Further material on consonants
5.1 Other pronunciation problems of Spanish language
5.2 Syllabic consonants
5.3 Classification of consonants
6 Further material
6.1 Diaphragmatic breathing
6.2 Speech articulators
6.3 Tongue shapes
1 Introduction
This article is the natural continuation of Pronunciation of American English vowels, that is, the study of American English consonants. All the remarks made at the outset of that article still hold true. Repetition, if not founded on the right pillars, is futile. Teaching pronunciation by mere repetition is methodologically fruitless and conceptually amiss. In no other subject we find such a powerful enemy, our own brain, willing to interfere student’s learning. As students of English as a second language, we all are well equipped with our mother tongue. Our brain is slothful, craves for the familiar, and adamantly rejects the unknown. Yet we all have the same articulatory organs. The difficulty in learning pronunciation lies in psychological factors, not in physiological factors. Before the unexpected, our brain tries to adapt the new sounds to the familiar repertoire of sounds of our mother tongue. Therefore, in order to attain a good pronunciation new articulatory habits must be taught. Those habits have to be instilled by explaining what articulatory organs are involved and how they produce those new, funny sounds. In the words of Peter Roach [Roa09], “pronunciation is an acquired skill.” Once those new sounds have been internalized, then repetition is the key to success, the mother of learning. A grammar rule can be understood instantaneously and, with some extra effort, master it. When learning a new sound, our brain has to familiarize itself with it, study its features, understand it in context, hear it pronounced with different accents; and then, but not before, as perception precedes production, our brain is all set to properly pronounce the new sound. Hence, practice from knowledge, be aware of each gesture, of each sound, of each organ. With time, the new sounds will become old friends, you will forget the technical explanations and just feel whether a produced or heard sound is conformable to language’s nature.
Description of consonant sounds implies a more complicated interaction of articulatory organs than in the case of vowel sounds. For that reason, in the next section we will examine the anatomy of speech organs. Building awareness of the organs involved in speech and how they participate in sound production will handsomely contribute to a good pronunciation. After that, we will study the American English consonants in detail. This will include, among others, variants of sounds /p/, /t/, /r/, and glottal stops. Finally, we will look at semivowels /j/ and /w/, which are sounds sharing features of both vowels and consonants. Throughout this article the symbols adopted by the International Association of Phonetics (IPA) will be used to represent sounds; see their official website [Ass] for more details on the IPA alphabet or [Wik]. Definitions will be given in boldface, examples and spellings will be given in italics, and sound transcriptions will go within forward slashes / / for broad or phonemic transcriptions and within square brackets [ ] for narrow or phonetic transcriptions (see Section 3.1subsection).
To illustrate the sounds explained in this article, we have again borrowed the excellent videos from Rachel’s English [Eng12]. The symbols used in those videos are mostly IPA symbols. Unless stated otherwise, all phonetic transcriptions will be given in American English. As some complicated anatomy words will appear in the text, we will provide the reader with the phonetic transcription as appropriate.
Experience has taught us that the articulatory habits of a student’s mother tongue cannot be ignored when teaching a new language. They inevitably interfere in the acquisition of the new articulatory habits. That interference is explained through many causes such as orthographic interference, different consonant and vowel distributions, differences in phonemes and allophones, contrastive features not used in one of the languages, disparate use of voicing, among others. Throughout the description of the consonants in this article we will point out to the main problems that can be found in the pronunciation of native Spanish speakers. Our purpose idea is to illustrate how to correct pronunciation in an effective manner.
2 Anatomy of speech organs
In many languages speech sounds are produced by modifying the airstream coming from the lungs. These modifications may take place in many ways, but two are of utmost importance: voicing, or making the air vibrate through the vocal cords; and disturbances caused by the organs in the upper vocal tract, such as tongue, lips, teeth, etc. We will divide our study of the organs involved in speech production into two steps, the first being the study of the organs from lungs to larynx, the second being the study of the upper vocal tract.
2.1 From lungs to larynx
Air is stored in our lungs. When we want to breath out, our chest is contracted, helped by the diaphragm/ˈdaɪəfræm/, an umbrella-like, powerful muscle, and air is expelled from the lungs, passing through two short tubes, the bronchi1 /ˈbrɑ:ɳkaɪ/; see Figure 1 (it has been taken from Antranik.org). Air comes in two different streams from the lungs and both merges at the bottom of the trachea. The trachea2 /ˈtreɪkiə/, also called the windpipe, is a tube joining the bronchi and the larynx. Inside the trachea the air flows freely as it is a hollow tube.
When the airstream reaches the end of the trachea, it then passes through the larynx. The larynx3 /ˈlærɪɳks/ is a sort of hollow box made of cartilage designed to contain the vocal cords, also called vocal folds. The front of the larynx is more prominent than the back (even more in the case of males) and is called Adam’s apple. The vocal cords consist of two sheets of muscle tissue, running parallel to each other, placed perpendicularly to the trachea, and spanning from back to front of the larynx; see Figure 2 on the left (Figure taken from Anatomy and Physiology Lab website at Florida Atlantic University). The space between the vocal cords is called glottis/ˈglɑ:tɪs/. Three positions can be adopted by the vocal cords: a close position, where the vocal cords are brought together and seals off the larynx cavity (again Figure 2, on the left); an open position, where the vocal cords are completely pulled apart and let the airstream go through with no obstruction (Figure 2, on the right); and near-close position, where the vocal cords are almost in contact, but in a loose way (see the video in Figure 3). The close position occurs when swallowing; that prevents foreign bodies to enter into the lungs and cause choking. The open position occurs when breathing normally. The near-close position occurs when speaking and singing. The vocal cords may take up other particular positions, as in whispering or murmuring; see [ODK97], Chapter 2, for a description.
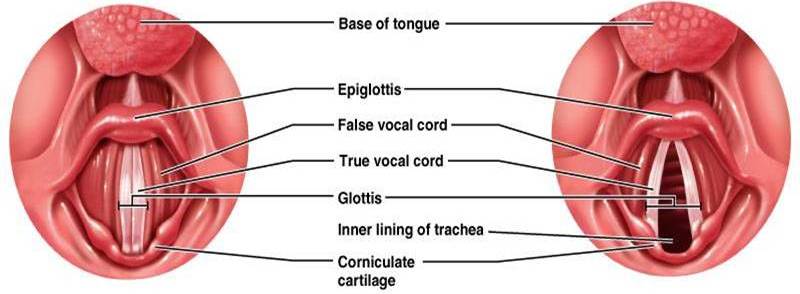
The vocal cords have freedom to move subject to certain limits. They are attached to two cartilages: posteriorly to the arytenoid/ˈərɪˈti:nɔɪd/ cartilages, and anteriorly to the thyroid/ˈɵaɪrɔɪd/ cartilage. The arytenoid cartilages can move so that vocal cords are pulled apart when necessary. In Figure 3 there is a video showing how vocal cords work (stroboscopy of a healthy woman; video taken from Voicedoctor.net). Vocal cords in the video are the pearly white stripes (they are white due to scant blood circulation).
In the video we can observe several interesting behaviours of the vocal cords. The length of the vocal cords is changed by the action of the larynx cartilages, which affects pitch. The longer the vocal cords, the higher the pitch. Although it cannot be appreciated in the video, the vocal cords can change their tension and therefore their resistance to the airstream. Those tension changes also modulate the pitch. The greater the tension, the higher the pitch. The vocal cords vibrate controlled by the vagus/ˈveɪgəs/ nerve. Actually, the final pitch is a combination of tension and length adjustments made by the vocal cords.
A particular sound may or may not be produced with the vocal cords in vibration. The quality of the sound changes enormously when vocal cords vibrate as the sound is enriched with harmonics. A sound is to said to be voiced if it is produced with the vocal cords in vibration; otherwise, it is called voiceless or unvoiced. All vowels are voiced. In English, voicing – the quality of being voiced, also called phonation – is of paramount importance. Most English consonants are paired by voicing; later on we will discuss this in depth. For example, voiceless sound /p/ has a voiced counterpart, sound /b/; the same occurs with other voiceless-voiced pair of sounds: /s/ and /z/, /t/ and /d/, or /f/ and /v/.
It is critical to the student of English to be able to tell when a sound is voiced or voiceless. In English, voicing is contrastive, that is, different words can only differ by voicing; compare pet/pet/-bet/bet/, sip/sɪp/-zip/zɪp/, or fan/fæn/-van/væn/. After having consolidated its perception, production of voicing is the next step. Try to use sounds that can be sustained in time like /s/-/z/ or /ʃ/-/ʒ/ rather than short sounds like /t/-/d/ or /k/-/g/. For example, alternate /s/-/z/-/s/-/z/-/s/-/z/... It should be clear which one is voiced from the sound. If still in doubt, feel your larynx vibrate by placing your hand on your Adam’s apple while pronouncing a voiced sound, or even better by placing your fingers firmly over your ears.
2.2 The upper vocal tract
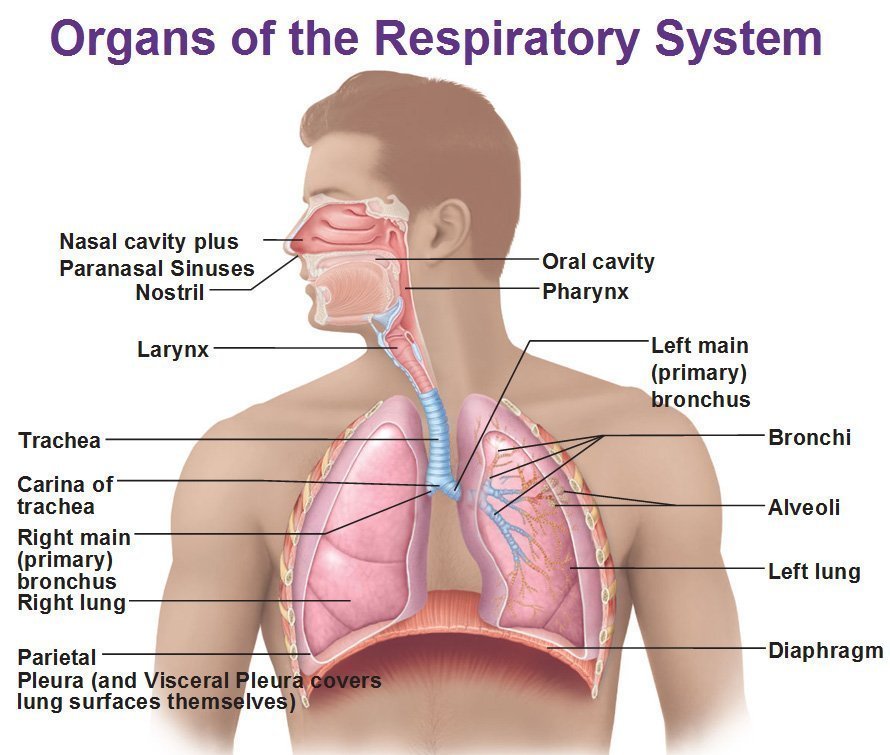
Once the air is expelled from the lungs and passes through the larynx, it reaches the upper vocal tract. This term refers to all organs and spaces from larynx to mouth. The upper vocal tract is divided into the oral tract, the mouth and throat cavities, and the nasal/ˈneɪzl/ tract, the nasal cavity. Next, we will describe all articulatory organs in the oral tract; use Figure 4 for reference and study.
2.2 The upper vocal tract
Once the air is expelled from the lungs and passes through the larynx, it reaches the upper vocal tract. This term refers to all organs and spaces from larynx to mouth. The upper vocal tract is divided into the oral tract, the mouth and throat cavities, and the nasal/ˈneɪzl/ tract, the nasal cavity. Next, we will describe all articulatory organs in the oral tract; use Figure 4 for reference and study.

|
- The lips. They take part in sound production in both vowels and consonants. In vowel pronunciation their position determines the roundness of the vowel. For example, /u:/ is a rounded vowel, but /æ/ is unrounded. In the case of vowels, lips can adopt three positions: rounded or lips projected forwards, unrounded or neutral lip position, and spread or lips stretched back. For more details on vowel pronunciation, see [Góm12b]. In the case of consonants, lips are involved in sounds such as /p/ or /m/, as in pet or man, and also in semivowels such as /w/, as in wood. Except for a few consonants, the lips are passive articulatory/ɑ:rˈtɪkjulətɔ:ri/ organs, that is, they do not move to produce the sounds.
- The teeth. They take part in consonant sounds such as /ɵ/ or /v/ (as in thought or van). The upper front teeth are usually involved in the production of sound rather than the bottom front teeth.
- The roof of the mouth. As a whole, it constitutes an important passive articulatory organ. From front to back, it can be divided into the alveolar ridge, the hard palate and the soft palate.
- The alveolar ridge/ælˈvi:ələr ˈrɪʤ/, also called the teethridge/ˈti:ɵˈrɪʤ/. The roof of the mouth does not make a perfect circular arch. The alveolar ridge starts just at the rear of the upper front teeth and slopes gently towards the interior of the mouth. At certain point there is a bulge, from which the actual arch of the roof of the mouth starts. The alveolar ridge is the area comprised between the rear of the upper front teeth and that bulge. Pull gently your tongue from the teeth to the bulge to feel the shape of the alveolar ridge. It is also a passive articulatory organ and appears in the production of sound such as /t/ or /z/, as in ten/ten/ or zoo/zu:/.
- The hard palate/ˈpælət/. After the alveolar ridge the hard palate is found, the arch formed by the roof of the mouth. Within the hard palate two regions are distinguished, the post-alveolar/poʊstælˈvi:ələr/ region, found immediately after the alveolar ridge, and the palatal/ˈpælətəl/ region, the rest of the hard palate. The hard palate is a passive articulatory organ, which is used, for example, to make sound /j/, as in yore/jɔ:r/. Again, feel it with the tip of your tongue.
- The velum/ˈvi:ləm/ (plural, vela/ˈvi:lə/) or soft palate. The final part of the roof of the mouth is made of soft tissue, unlike the hard palate, which is made of hard bone. Although the tongue has to be bent quite a lot, it is possible to feel the soft palate with the tip. Sounds like /k/ or /g/, as in can/kæn/ or go/goʊ/, are produced by using the soft palate. However, apart from sound production, the main role played by the soft palate is sealing off the nasal tract. That allows the distinction between oral sounds and nasal sounds. Oral sounds are produced when the air only passes through the oral cavity. For that to happen, the soft palate has to be raised so that the entrance to the nasal cavity is sealed off. If the soft palate is at neutral position, just hanging, then part of the sound goes through the nasal cavity. That gives sound a special quality, the so-called nasal quality (nasality/neɪˈzælɪti/).
- The uvula/ˈju:vjələ/. The soft palate ends in a conic projection called uvula. It is described here for the sake of completeness, but the uvula is not involved in any English sound.
- The tongue. The tongue is the articulatory organ. Unlike most organs described so far, the tongue is an active articulatory organ, that is, it moves to produce the sounds. The tongue is very flexible and moves in quite subtle ways. It can bend backwards, it can raise or lower several parts, it can move backwards or forwards, it can protrude and retrude, it can twist, it can form grooves through its medial axis, and it can touch other articulatory organs in a number of ways; see [HP03] and [SL96] for information on models of the tongue and its movements. The tongue is controlled by a complex and large group of muscles, as shown in Figure 5 (taken from Medica Look), which include horizontal, vertical, transverse, and longitudinal muscles.
In order to describe sound production precisely later on, we will distinguish the following parts in the tongue:
- The tip, or the thin pointed end of the tongue.
- The blade. Phoneticians Ladefoged and Maddieson [LM96] gave a definition that has been used often because of its simplicity: “When the tongue is at rest in a closed mouth, the tongue blade is the part of the tongue that lies directly under the alveolar ridge.” That will be our definition, too.
- The front or body. This term is confusing because it is not the front it is referring to but the middle part of the tongue; see Figure 6. The front of the tongue is found after the blade. In sounds such as high, front vowel /i:/, it is the front of the tongue that comes near the roof of the mouth.
- The back. It is found after the front of the tongue and forms its posterior part. It is involved in sounds such /ʊ/ or /g/.
- The root. The root of the tongue is the part at the far back and bottom of the tongue. It is also part of the front wall of the pharynx. Again, the root is mentioned here for completeness, but it is not associated to any English sound.

Figure 6: Main parts of the tongue (after [LM96]).
Paradoxical enough, although it is known that tongue shape is perceptually relevant to speech sound production, very few books mention it when describing a sound. Tongue shape refers to the shape the tongue takes on when producing a sound. For some sounds, for example sibilants (see Section 3.3subsection), tongue shape is crucial to pronunciation. In this article basic basic tongue shapes are described.
- The pharynx/ˈfærɪɳks/ (plural, pharynges/fəˈrɪnʤi:z/). The pharynx is the area delimited by the larynx, the root of the tongue, and the soft palate; refer to Figure 4. The root of the tongue can move and change the width of the pharynx.

3 Consonants and semivowels
3.1 Phonemes and allophones
At this point it is in order to make a finer distinction in the concept of sound. The smallest unit of speech that distinguishes one word from another is called phoneme/ˈfoʊni:m/. For example, pet/pet/ and bet/bet/ are different by one sound; the initial sound in pet is a voiceless bilabial stop /p/ (precise descriptions later on), whereas in bet it is a voiced bilabial stop /b/. The presence of one sound or the other definitely changes the meaning of the word. However, in English sound /p/ can be pronounced in at least two ways, one as an aspirated sound [ph], which is strong and dry, occurring when the sound is on the syllable carrying the stress, and another as a softer, de-aspirated sound [p=] (superscript = is the IPA symbol for de-aspirated sounds). Again, technical details on how to pronounce these sounds will be given later. Strictly speaking, the first sound in pet should be [ph]. Yet exchanging the aspirated sound with the de-aspirated sound does not alter the meaning of word pet. No native English speaker would contend you are not understood because of your pronouncing pet as [p=et] instead of [phet]; at most he would say that you speak with a funny accent or your accent is thick. Different sounds that belong to the same phoneme and do not affect meaning are called allophones. Sounds [ph] and [p=] are allophones of the same phoneme /p/. Allophones are also said to be non-contrastive sounds, whereas phonemes are said to be contrastive sounds.
In order to make the text of this article easy to follow, we will try to use as few symbols as possible as long as clarity and precision is ensured. Some authors write phonemes in forward slashes / / and allophones in square brackets [ ]. We will follow that notation here with some restrictions. Only when narrow transcriptions (at the level of allophones) be really necessary for the discussion, we will use square brackets. Otherwise, we will try to use forward slashes. The context and usage rules will make clear what sounds are being referred to. For example, in general, de-aspirated sounds will not be notated (the superscript = will be dropped), but aspirated sounds will.
Phonology is the branch of linguistics concerned with the study of sounds in languages as abstract categories describing function and structure. Phonetics is concerned with physical properties of speech sound as well as with its production and perception. Phonology studies the phonemes of a language because they are the categories used by the speakers to extract meaning out of the speech sounds. Phonetics describes how the sounds of a language are produced (articulatory phonetics), how the speech sounds are transmitted from speaker to listener (acoustic phonetics), and how the listener perceives the speech sounds (auditory phonetics). As an example of the distinction phonology-phonetics, consider phoneme /t/ and its allophones in English. This phoneme can be pronounced up to seven phonetically different ways (again, precise details will be given later): as an aspirated sound [th], as a de-aspirated sound [t=], as an unreleased sound [t˺], as a glottal stop [ʔ], as a glottalized t [tʔ], as a flap t [ɾ], and as an omitted sound [∅] (represented here by the symbol ∅). In Figure 7 several words where those allophones take place are shown. See [PBL+06] and [Hay08] for a deeper discussion on phonemes and allophones.

3.2 Description of consonants and semivowels
A common way to define a consonant is as a sound produced by a partial or complete obstruction of the airstream (see [AE92], [LM96], [Bal12], for example, where this definition is either given explicitly or simply implied). This definition accounts for most of sounds considered as consonants in the English language, such as /t/, /g/, /f/, or /ʤ/. However, some sounds are produced like vowels, but they always function as consonants; they are the so-called semivowels. In the case of the English language, semivowels are sounds /j/, as in yes/jes/, and /w/, as in well/wel/. Surprisingly enough, some sounds that are considered as consonants in a language may be considered as vowels in other languages. For instance, sound /r/ is a consonant in English, both by manner of production and function, but it is a vowel sound in some Slavic languages. A broader definition of consonant is given by phonetician Ian Maddieson ([Sev12], Chapter 1). Following his definition, a consonant is a sound typically occurring at the syllable margins as opposed to vowels, which are sounds typically occurring in the syllable centers; we will come back to this matter in Section 4.6subsection. In this article we will classify consonants both in terms of manner of sound production and function. Therefore, /j/ and /w/ will be regarded as consonants. However, we will still call them semivowels to make emphasis on their manner of production. For an insightful, concise discussion of the definition of consonant, the reader is referred to [Roa09].
From a sound production standpoint, we have established that in consonants there is a partial or complete obstruction of the airstream. That obstruction mainly takes place in the upper vocal tract, and in a few cases, the glottal consonants, in the larynx. Two factors are involved in the consonant production, namely, what organs are used to produce the sound—place of articulation —, and how the sound itself is produced—manner of articulation and voicing—. This gives rise to the following classification of consonants.
- By place of articulation, that is, where in the vocal tract the obstruction of the airstream takes place, and which speech organs are involved; see Figure 8.
- Bilabial/ˈbaɪˈleɪbiəl/ consonants, when both lips are involved, as in /p/ or /m/.
- Alveolar/ælˈvi:ələr/ consonants, when the alveolar ridge is used, as in /t/ or /z/.
- Post-alveolar/poʊstælˈvi:ələr/ consonants, when the posterior part of the alveolar ridge is used, as in /ʧ/ or /ʒ/.
- Labio-dental/ˈleɪbioʊˈdentl/ consonants, when the consonant is produced by using the front teeth and the lower lip, as in /f/ or /v/.
- Dental/ˈdentl/ consonants, when both upper and bottom front teeth are involved, as in /ɵ/ or /∂/.
- Velar/ˈvi:lər/ consonants, when the soft palate is involved, as in /k/ or /ɳ/.
- Glottal/ˈglɑ:tl/ consonants, when the glottis is used, as in /h/ or /ʔ/.
The possible places of articulation are shown in Figure 8. Some places are not used in the English language.

Figure 8: Different places of articulation (after [LM96]). - By manner of articulation, that is, the actual manner of articulating the consonant.
- Stops or plosive/ˈploʊsɪv/ consonants: The airstream is blocked by two articulatory organs, then held for some time, and finally released, which causes the production of the sound. Stops are, for instance, /p/, /d/, /g/, or /ʔ/. Different organs participate in the production of each of those sounds.
- Fricatives/ˈfrɪkətɪvz/: There is a partial obstruction of the air produced by placing two organs very close together. An example of a fricative is /f/, where the two organs involved are the upper teeth and the lower lip. In this case, the airstream escapes between both organs through a narrow passage and thus the sound is produced. Other examples of fricatives are /s/, /ɵ/, and /ʃ/.
- Affricates/ˈæfrɪkət/: A consonant that begins as a stop and is released as a fricative. In English there are two affricate sounds, /ʧ/ and /ʤ/.
- Nasals/ˈneɪzl/: In this kind of consonants the air can escape freely from the nose as well as from the mouth. Nasal consonants in English are /m/, /n/, and /ɳ/.
- Approximants/əˈprɑ:ksɪmənt/: The sound is formed by the coming of two articulators close together but not as much as in the case of fricatives. Within the approximants, two class of sounds can be distinguished in English, the r-consonants and lateral approximants. Both will be described in detail below. Examples of approximants in English are /ɹ/ (r-consonant) and /l/ (lateral approximant).
- By voicing. Before reaching the upper vocal tract, where the consonant sound is produced, the air passes through the vocal folds. If they vibrate during the articulation of the sound the consonant is voiced; otherwise, it is said to be voiceless or unvoiced. This distinction is very important not only in terms of the quality of sound (different timbre) but also for grammatical reasons, as we will see later.
Table 1 shows the consonant sounds found in English. When consonants are shown in pairs, voiceless consonants appear to the left of the black bullet and voiced consonants to the right. Main allophones have also been included in the Table, which will be explained in detail later.

|
3.3 Voicing of consonants
The distinction of consonants by voicing is essential in English and therefore crucial to acquiring good listening skills. Minimal pairs are pairs of words that only differ by one sound, such as pull/pʊl/-pool/pu:l/ or eat/i:t/-it/ɪt/. Minimal pairs based on voicing are very common in English. Those are pair of words where all sounds are identical except for one whose voicing is different. Consider pairs pet/pet/-bet/pet/, sip/sɪp/-zip/zɪp/, ten/tend/-den/den/, or chin/ʧɪn/-gin/ʤɪn/; the only difference between each pair is the voicing at the initial sound, enough to alter their meaning. John Higgins has compiled a complete and illustrative table of minimal pairs for British English; see [Hig]. Regrettably, we do not of any comprehensive compilation of minimal pairs for American English. The following table shows the English consonants paired by voicing (voiceless are on the left and voiced on the right).

|
Consonant sounds that are not paired by voicing are the following:
- Voiced sounds: nasals /m/, /n/, and /ɳ/; r-consonants /ɹ/, /ɾ/, and /ɻ/; lateral approximants /l/ and /lɤ/; and semivowels /j/, and /w/.
- Voiceless sounds: fricative /h/ and stop /ʔ/.
In addition to the semantic distinction given by minimal pairs, voicing also governs other important cases. Voicing may determine grammatical function. For instance, use/ju:s/ is a noun pronounced with voiceless sound /s/, but as a verb use/ju:z/ is pronounced with voiced sound /z/. Another important case is that of pronunciation of plurals, possessives and third person of present simple. Again, they are also formed according to voicing. In order to explain how those grammatical cases are formed, we need to introduce a special type of consonants called sibilant/ˈsɪbɪlənt/ consonants. A sibilant consonant is either a fricative or an affricate consonant where the tongue makes a groove through which the airstream is directed. The groove is central so that the airstream flows across the centre of the mouth over the tongue. Table 3 lists the sibilant consonants found in English.

|
Having defined sibilant consonants, we are now in the position of setting out the rules for the pronunciation of the plural of nouns.
- If a word ends by a vowel sound, then its plural will be pronounced by adding the sound /z/. For example:
- Eye/aɪ/
 eyes/aɪz/.
eyes/aɪz/. - Bee/bi:/bee/bi:z/.
- Law/lɔ:/laws/lɔ:z/.
- Eye/aɪ/
- If a word ends by a non-sibilant sound, then its plural will be pronounced by adding sound /s/ when it is a voiceless consonant, and by adding sound /z/ when it is a voiced consonant. For example:
- Pet/pet/pets/pets/ (voiceless case).
- Dog/dɑ:g/dogs/dɑ:gz/ (voiced case).
- Folk/foʊk/folks/foʊks/ (voiceless case).
- Coin/kɔɪn/coins/kɔɪnz/ (voiced case).
- Pet/pet/
- If the word ends by a sibilant sound, then the plural is pronounced by creating a new syllable /ɪz/. For example:
- Beach/bi:ʧ/beaches/ˈbi:ʧɪz/.
- Bridge/brɪʤ/bridges/ˈbriʤɪz/.
- Bush/bʊʃ/bushes/ˈbʊʃiz/.
- Garage/gæˈrɑ:ʒ/garages/gæˈrɑ:ʒɪz/.
- Bus/bʌs/buses/ˈbʌsɪz/.
- Rose/roʊz/rose/ˈroʊzɪz/.
Exceptions to the previous rule can also be found (irregular plurals):
- House/haʊs/houses/ˈhaʊziz/.
- Mouths/maʊɵ/mouth/maʊ∂z/.
- Bath/bæɵ/baths/bæ∂z/.
- Beach/bi:ʧ/
Moreover, the same pronunciation rules are applied to possessives (Saxon genitive):
- Mark/ma:rk/Mark’s/ma:rks/.
- Joe/ʤəʊ/Joe’s/ʤəʊz/.
- George/ʤɔ:rʤ/George’s/ˈʤɔ:rʤɪz/.
When the third person of singular of present simple is written, it takes either an s or an es. The pronunciation of the new added consonant follows the same rules as in the plural.
- I lie/aɪˈlaɪ/He lies/hi:ˈlaɪz/ (vowel syllable-final case).
- I want/aɪˈwɑ:nt/He wants/hi:ˈwɑ:nts/ (voiceless non-sibilant case).
- I read/aɪˈri:d/He reads/hi:ˈri:dz/ (voiced non-sibilant case).
- I teach/aɪˈti:ʧ/He teaches/hi:ˈti:ʧɪz/ (sibilant case).
The previous examples should have made clear how significant voicing is. Voicing should be perceived with crystal clarity and produce with great precision if an intelligible pronunciation is pursued.
4 The American English consonants
4.1 Stops
Stops or plosive consonants. The sound is produced in three stages; see Figure 9:
- Closure/ˈkloʊʒər/: the oral cavity is completely blocked by the speech organs involved.
- Blockage/ˈblɑ:kɪʤ/: The oral cavity is held blocked for some time (some milliseconds). The air from the lungs continues to come into the oral cavity. Therefore, the air pressure inside the oral cavity increases. This stage is also called compression/kəmˈpreʃn/ stage.
- Release: Finally, the blockage is released. Due to the air pressure difference between the oral cavity and outside, the air is expelled with a burst or puff (hence, the name of plosive).

|
According to the organs involved in the closure of the oral cavity, stops are classed as follows:
- Bilabial stops: the airstream is held by using both lips. Bilabial stops are [ph], [p], [p˺], and [b].
- Alveolar stops: the airstream is held by pushing the tip of the tongue against the alveolar ridge. Alveolar stops are [th], [t], [t˺], and [d].
- Velar stops: the airstream is held by pushing the back of the tongue against the soft palate. Velar stops are [kh], [k], k˺, and [g].
- Glottal stops: the airstream is held by closing the vocal folds (remember that the space between the vocal folds is the glottis). Glottal stops are [ʔ] and [tʔ]. Sound [ʔ] is a pure glottal stop, not associated to any other sound, while [tʔ] is a co-articulation of [t] and [ʔ] (see Section 4.1.5subsubsection).
Stops can be either voiced or voiceless. When they are voiceless, three allophones or variants arise, the aspirated/ˈæspərətɪd/ sound, the de-aspirated/di:ˈæspərətɪd/ sound, and the unreleased sound. Aspiration will be indicated by writing a superscript h, as in [ph]; de-aspiration by the absence of superscript; and when unreleased by superscript ˺.
How does aspiration work? Sometimes, a plosive is located between two vowels. If the stop is voiced, the vocal cords will continue vibrating. However, if the stop is voiceless, the vocal cords will stop vibrating for some time. If they start vibrating after the release stage, the stop will be aspirated (see Figure 9, bottom). When the vocal cords start vibrating before the release stage, that vibration disturbs the air coming from the lung, making the air pressure decrease; the burst is not as intense as in the previous case. Therefore, the stop will be de-aspirated (see Figure 9, middle). Similar situations can be found when a plosive sits between other consonant sound, particularly fricatives.
All aspirated sounds follow the same rules for their pronunciation.
- Voiceless stops are aspirated when they begin a stressed syllable, no matter if it is not the first syllable of the word. Examples: opinion[əˈphɪnjən], ten[then], recall[ɹɪˈkhɔ:l].
- When it is the first sound of a word irrespective of where the stressed syllable is, as in tempting[ˈthemp˺tɪɳ], or potential[phəˈthenʃl]
- Voiceless stops are de-aspirated when the first sound is [s], as in spot[spɑ:t], stop[stɑ:p], or skunk[skʌɳk] (no superscripts).
- Word-final voiceless stops optionally can be aspirated. Sometimes this depends on emphasis, speech speed, or the particular accent.
As for rule 3, some authors contend (Rachel herself [Eng12], for example) that in clusters formed by sound [s] plus a plosive, the plosive is still aspirated. We think that in a very emphatic enunciation that might be the case, but in general we incline to the view that those plosive are de-aspirated. Davidsen-Nielsen [DN69] looked into this question carefully. He found that native speakers perceive sounds [p], [t], and [k] as [b], [d], and [g], respectively, when those sounds are isolated from pairs [sp], [st], and [sk]. It seems that in the case of [s] followed by voiceless plosive plus vowel the vocal cords start vibrating much earlier than in other cases. This fact prompted Davidsen-Nielsen to even propose transcribing [sp], [st], and [sk] followed by vowel as [sb], [sd], and [sg]. The tenet in phonetics is that in general plosives before fricatives are de-aspirated, as in after[ˈæft=əɻ] or ashtray[ˈæʃt=ɹeɪ]. For more information on this issue, see [DN69], [Roa09], [Gie92], [Wel90], and the references therein.
Finally, let’s describe the third allophone of plosive phonemes, the unreleased stop. In this sound the blockage is still created, but much less air is accumulated behind the speech organs, and the release is not audible. It appears in word-final positions, specially in colloquial speech, as in cat[khæt˺] or in the presence of stop clusters, such as in apt[ˈæp˺t], doctor[ˈdɑ:k˺tər], or logged on[ˈlɑ:g˺dɔ:n]. In the latter case, both stops are somehow merged into one and the release of the first stop is removed. In the video in Figure 11 we can see an example where plosive [p] is unreleased so that the next word can be properly stressed in the sentence. Unrealeased stops are frequent in voiceless consonants and to a lesser extent in voiced consonants.
4.1.1 Bilabial sounds [ph], [p], [p˺], and [b]
The closure of the oral cavity is carried out by the lips, which come together to stop the airstream. Then the airstream is held just behind the lips, and finally is released; see Figure 10. There are three voiceless allophones, [ph], [p], [p˺], and one voiced allophone, [b]. Spellings commonly associated with bilabials are p, pp for sound [p], as in pen[phen], happy[ˈhæpi], or lap[læp˺], and b, bb for sound [b], as in best[best] or robber[ˈrɑ:bər].

|
In this video Rachel describes all allophones of phoneme /p/ (she notates the unreleased stop by [p∣] instead of the IPA symbol [p˺]).
Aspiration does not exist in Spanish and in general Spanish speakers tend not to aspirate bilabial stops in word-initial position. This makes their accent unpredictable and of blurry outline.
4.1.2 Alveolar sounds [th], [t], [t˺], and [d]
In alveolar sounds the closure is produced by the tongue blocking the airstream against the alveolar ridge; see Figure 12. In order to do so, the tongue widens to seal off the oral cavity. It is the blade of the tongue that makes contact with the alveolar ridge; the tip of the tongue is in rest position just behind the upper front teeth. As in the case of voiceless bilabial stops, there are an aspirated and de-aspirated allophones.

|
In some languages, such as Spanish, phoneme /t/ is pronounced as a dental stop[t̪ ], that is, the place or articulation is at the behind the upper teeth instead of the alveolar ridge; see Figure 13. Although pronouncing phoneme /t/ as a dental consonant is not contrastive, it sounds unnatural to native ears and therefore students should attach importance to it. Again, Spanish speakers may not aspirated /t/ in word-initial position.

|
Common spellings of phoneme /t/ are:
- t and tt, as in ten[then], stop[stɑ:p], or wait[weɪt˺].
- The past simple of a regular verb ends in phoneme /t/ when the last sound of the verb is a voiceless sound different from /t/: trip[thrɪp]tripped[thrɪp˺t], ask[æsk]asked[æsk˺t], laugh[læf]laughed[læfth], toss[tɑ:s]tossed[tɑ:sth], mash[mæʃ]mashed[mæʃth]. Past simple endings are often aspirated to clearly distinguish them from other tenses. Past simple endings are seldom unreleased.
- Spelling th, although less frequent, can be found, as in Thailand[ˈthaɪlænd].
In this video Rachel describes all allophones of phoneme /t/ and the pronunciation of letter t as an alveolar flap [ɾ]. This sound is actually an r-consonant and will be covered in Section 4.5.1subsubsection.
In this video Rachel covers the pronunciation of letter t, which certainly includes the allophones studied in this Section. The video is shown here for the sake of completeness.
This Rachel video is a follow-up where the reader is provided with many practical examples of how to pronounce letter t, incidentally to pronunciation of phoneme /t/:
The main problem native Spanish speakers have with alveolar stops has already been pointed out: the pronunciation of alveolar /t/ as a dental /t̪ /. This is an important mispronunciation to correct as sound /t/ is common in English and appears in many consonant clusters.
4.1.3 Velar sounds [kh], [k], [k˺], and [g]
In velar sounds the closure is produced by the back of the tongue leaning against the soft palate, which blocks the airstream; see Figure 17. Similarly to bilabial and alveolar stops, aspirated, de-aspirated, and unreleased allophones ( [kh], [k], [k˺]) can be observed. When the stop is voiceless, sounds [kh], [k], and [k˺] are produced. If the stop is voiced, sound [g] results.

|
Common spellings of phoneme /k/ are:
- Letter c in word-initial, as in cat[khæt], and also within a word, as in fact[fæk˺t].
- Letter k in word-initial, as in keep[ki:p], and also within a word, as in like[laɪk].
- Combinations ck and ch, as in black[bæk] and school[sku:l].
- Combination qu, as in quiet[khwaɪət].
- Letter x, as in six[sɪks].
Sound [g] is normally spelled g or gg, as in girl[gɜ:rl] or egg[eg].
In the video below only [kh], [k], and [g] are explained.
Spanish speakers also have problems pronouncing sound [g]. This sound is not equivalent to the corresponding [g]-sound in Spanish, which is a velar approximant [ɤ̞]. Spaniards unaware of the pronunciation of sound [g] replace this sound with sound [ɤ̞]. This is the reason why many Spaniards do not pronounce perfectly words as simple as good. In fact, so soft is the Spanish pronunciation of good (the [g]-sound in general) that native English speakers often confuse it with wood. This feature has to be taken care of if a polished accent is to be acquired. For more information on this topic, see [Mot11] for technical details (such as actual blockage times), [Yav07] for comparative phonology, or [Wik12a].
4.1.4 Glottal sound [ʔ]
A glottal stop is a voiceless sound produced by the closure of the glottal space by the vocal cords. Since it is a stop, there is blockage stage after which the air is released.
The glottal stop is an allophone of phoneme /t/. Normally, it substitutes the de-aspirated sound [t]. Rules for such a substitution are the following:
- The glottal stop appears at the end of words, as in put[puʔ] or report[rɪˈpɔ:rʔ].
- The glottal stop also occurs in the presence of a stressed syllable followed by:
- A nasal vowel, specially with patterns [t+vowel+n] or [tn], as in button[ˈbʌʔn], or continent[ˈkɑ:nʔɪnənt]. This is the most frequent case both in American and British English.
- A fricative or a stop, as in outside[ˈaʊʔˈsaɪd], patsi[ˈpæʔsi], football[ˈfʊʔbɔ:l], outfall[ˈaʊʔfɔ:l].
- a semi-vowel [j] or [w], or sound [l]. Examples are right way[ˈraɪʔweɪ], can’t you?[ˈkænʔju:], or brightly[ˈbraɪʔli].
For more information on the glottal stop, see [Roa09] (for a good explanation of its anatomy), as well as [AE92], [Wel12], [LM05], [Wik12b], [LM96]. David Brett [Bre12] wrote a nice article where he gives several examples of glottal stop, including excellent sound files. The next video by Jennifer [Jen12] explains very clearly how glottal stops work in American English. Warning: sometimes, depending on how the video is recording or the sound system where it is played back, it is difficult to perceive the sound of a glottal stop.
Glottal stops are found both in British and American English as allophones of phoneme /t/. In the case of British English the use of glottal stops is extended to other voiceless stops, such as /p/ and /k/ in word-final, as in rocker/ˈrɒʔə/ or upper/ˈʌʔə/. An extreme case is the dialect known as Cockney English, where word-final /t/ is substituted by [ʔ] systematically. In the video below Richard from Linguaspectrum puts forward examples from Cockney accent.
4.1.5 Glottalized sound [tʔ]
A glottalized/ˈglɑ:təlaɪzd/ stop is the occurrence of a glottal stop at the same time or just immediately after another consonant. This is represented in IPA by adding ʔ as a superscript to the main sound. Consonants that are formed by the production of two simultaneous sounds are called co-articulated consonants; glottalized stops are thus co-articulated consonants. In American and British English the most common glottalized stop is [t], which is accordingly represented by [tʔ]. This phenomenon also receives the name of glottal reinforcement. In a glottalized [tʔ] the stop [t] and the glottal stop [ʔ] are produced at the same time or [ʔ] right after [t]. For its production, this allophone follows the same rules as the glottal stop does. Example of glottalized t are mutton[ˈmʌtʔn], or curtain[ˈkɜ:rtʔn].
Glottal reinforcement can be found in British English to strengthen [ʧ] or [tr] at the end of a syllable, among other cases; see [Wel12] for a thorough discussion and [Bre12] for actual examples of glottal reinforcement. For more information about glottal reinforcement and glottalized t, see [Chr52], and [LM96].
4.2 Fricative sounds
In fricative consonants there is a partial obstruction of the air produced by placing two articulatory organs very close together. Normally, one of the organs is a passive articulator (see Section 2.2subsection) and the other is an active articulator (the tongue in most cases). The narrow passage causes a turbulent airstream, which produces the fricative sound. The sound produced by the turbulent airstream is called frication/fraɪˈkeɪʃn/. According to the organs involved in the partial obstruction of the oral cavity, fricatives are classified as follows:
- Labio-dental sounds: The frication is caused by loosely placing the upper teeth on the bottom lip. Labio-dental sounds are [f] and [v].
- Dental sounds: The frication is caused by placing the tongue between the upper and bottom teeth. Dental sounds are [ɵ], [∂], and [∂̞].
- Alveolar sounds: The frication is caused by moving the blade of the tongue near the alveolar ridge. Alveolar sounds are [s] and [z].
- Post-alveolar sounds: The back of the tongue forms a narrow passage with the hard palate (post-alveolar) that results in the frication. Post-alveolar sounds are [ʃ] and [ʒ].
- Glottal sounds: The frication is achieved by putting the vocal folds in a near-close position and letting the air go through them. [h] is the only fricative glottal sound in English.
4.2.1 Labio-dental sounds [f] and [v]
The upper front teeth come close to the bottom lip, while the tongue is in rest position. The airstream is forced through the slit formed by those two articulators; see Figure 21. Consonant [f] is voiceless and consonant sound [v] is voiced.

|
Spellings f, ff, ph, and gh are frequently associated to sound [f]; see the following examples: first[fɜ:st], coffee[ˈkhɑ:fi], photo[ˈfoʊtoʊ], or cough[ˈkhɔ:f]. The only spelling associated to [v] is letter v.
The main problem Spaniards encounter with sound [v] is that this sound does not exist in Spanish. Letter v does exist and is pronounced either as [b] or as a bilabial fricative [ʱ], which causes mispronunciation.
4.2.2 Dental sounds [∂], [∂̞] and [ɵ]
The tip of the tongue is placed between the upper and bottom front teeth, making loose contact. The air is forced its way through the narrow passage formed by the teeth and tongue, which causes the frication characteristic of these sounds. There is a voiceless sound [ɵ], and two voiced allophones [∂] and [∂̞]. The latter is used when a word is not fully enunciated (in particular in the context of consonant reduction; see [AE92]). In [∂̞] the tongue does not go through the teeth fully, but just stays behind the teeth and presses them a little bit. This allophone is called a dental approximant. In the video in Figure 23 this sound is covered. Both phonemes /ɵ/ and /∂/ are associated to spelling th, as in thanks[ɵæɳks], these[∂i:z], or Tell me the time[thelmi:∂̞əthaɪm] (definite article the is often pronounced as the dental approximant).
Native Spanish speakers tend to devoice phoneme /∂/. The closest sound in Spanish is precisely phoneme /ɵ/, the voiceless counterpart of /∂/. Also problematic is the substitution of [∂] for [d] (or its equivalent sound in Spanish). This is due to the fact that [∂] never appears in word-initial position in Spanish, whereas [d] always does.
4.2.3 Alveolar sounds [s] and [z]
Sounds [s] and [z] have the same manner and place of articulation; they only differ in voicing. Sound [s] is voiceless, whereas sound [z] is voiced. As for their articulation, the blade of the tongue is raised towards the roof of the mouth. The tip of the tongue rests just behind the bottom front teeth; see Figure 24.

|
Furthermore, earlier on we defined sounds [s] and [z] as being sibilants. The tongue is thus curved along its medial axis, with its sides actually touching the alveolar ridge and forming a narrow passage or groove through which the airstream passes. That is the way this sibilant consonant is produced. Lips are parted and the corners pull back as in a smile. In Figure 25, which was taken from [LM96], we can see the articulatory gesture for [s] as in saw pronounced by Ladefoged. On the right, the solid line shows the position of the tongue, as extracted from x-rays, whereas the grey line indicates the position of the sides of the tongue, as given by palatograms. Between both lines, it is possible to imagine the exact tongue shape for this sound. On the left, it is shown a transverse view taken from the coronal section (indicated by the arrow on the left).

|
Note that in Figure 25 the tip of the tongue is not exactly behind the bottom front teeth as described above, but just behind the upper front teeth. There are certain positional variation for the tongue in this respect.
Consonant [s] has a quite characteristic high-pitched, hissing sound that other similar [s]-sounds from other languages do not to have. For example, compared to the Spanish [s]-sound, some differences with respect to the English [s]-sound can be perceived. Spanish [s] is apical[ˈæpɪkl], that is, it is produced with the tip of the tongue rather than with the blade (these consonants are called laminal[ˈlæmənəl]). Some authors even speak of a little retroflex (curling back) of the tongue in the case of the Spanish [s]-sound, which would account for differences in timbre and pitch (Spanish [s] is perceived as lower in pitch than English [s]).
In the video below Rachel explains both sounds [s] and [z] and pays close attention to tongue and lip position.
Common spellings of sound [s] are:
- Letter s in word-initial, as in son[sʌn], and also within a word, as in bus[bʌs].
- The formation of plural, third person of present simples, and Saxon genitive require adding an [s] if the word-final sound is a voiceless non-sibilant. See Section 3.3subsection on voicing of consonants above.
- Letter c in word-initial, as in city[ˈsɪɾi], and also within a word, as in pencil[ˈphensɪl].
- Spelling sc is sometimes pronounced as [s], as in scissors[ˈsɪzərz].
Common spellings of sound [z] are:
- Letter z in word-initial, as in zoo[zu:], and also within a word, as in easy[ˈi:zi].
- The formation of plural, third person of present simples, and Saxon genitive require adding an [z] if the word-final sound is a voiced non-sibilant and [ɪz] if the word-final sound is a sibilant, either voiced or voiceless. Again, check out Section 3.3subsection.
- Combination zz, as in dizzy[ˈdɪzi].
- Spelling ss is sometimes pronounced as [z], as in scissors[ˈsɪzərz].
Another pronunciation problem encountered among native Spanish speakers is that of the distinction of minimal pair [s]-[z]. Sound [z] does not exist in Spanish and is systematically replaced by voiceless sound [s̺ ], the apical version of English alveolar sound [s]. This is one of the main problems since voicing is phonemically very important in English.
In Spanish [s] in word-initial is always preceded by a vowel. This makes some native Spanish speakers to insert vowel [e] before [s] in words like stop, which is mispronounced [estɑ:p˺] .
4.2.4 Post-alveolar sounds [ʃ] and [ʒ]
The two post-alveolar sounds take the same tongue position, [ʃ] being the voiceless consonant and [ʒ] its voiced counterpart. In these sounds the front of the tongue is curled (hence, the term post-alveolar) and approaches the roof of the mouth without touching it; see Figure 27. The hard palate is a relatively large area. Here the tongue approaches the area immediately after the alveolar ridge (hence, the term post-alveolar) as opposed to palatal/ˈpælətl/ consonants, where the approximation takes place at the centre of the hard palate. Since it is also a sibilant consonant, the centre of the tongue forms a groove or channel. The sound is produced by the frication created when the airstream passes through that narrow passage. The tip of the tongue is relaxed and slightly touching the bottom front teeth. The lips are a little bit rounder to help channel the airstream.

|
Taken from the paper by Stone and Lundgerg [SL96], the tongue shape corresponding to sound [ʃ] is shown in Figure 28. This is a 3-D reconstruction by using spline interpolation from 2-D measures on the tongue. The groove characteristic of this sibilant sound is quite noticeable. The air is directed by the tongue through this groove along plane A and perpendicularly to plane B. See Section 6.3subsection for further discussion about tongue shapes and consonant pronunciation.

|
The most common spelling for [ʃ] is sh, as in shop[ʃɑ:p]; less common spellings are: c, as in ocean[ˈoʊʃn]; ch, as in machine[məˈʃi:n]; or initial s, as in sure[ʃʊr]. As for the voiced sound [ʒ], which is rare in English, it is normally spelled s or si, as in usual[ˈju:ʒəl] or Asia[ˈeɪʒə].
Here we have Rachel’s video explaining the pronunciation of these two sounds.
4.2.5 Glottal sound [h]
This is a complicated sound to describe from a technical point of view. By its manner of articulation it is classed as a fricative, although for some authors this sound lacks some basic characteristics of a consonant and is, therefore, treated as a vowel or a transitional[trænˈsɪʃənl] state of the glottis [LM96]. In this article it will be considered a glottal fricative. The sound [h] is produced by the vocal cords coming close together, without touching each another, and vibrating. Since the sound is produced in the larynx, the mouth position usually corresponds to the next sound in the word; see the video by Rachel below. In the video below around minute 0:45 we can see how the vocal cords produce sound [h].
Sound [h] is usually spelled h, as in here[hɪɻ].
In Spanish voiceless glottal fricative [h] is not present. The closest sound is [x], a voiceless velar fricative. Native Spanish speakers tend to substitute [h] for [x]. Since sound [x] is strong and somewhat rough as pronounced in Spanish, its use produces a quite unnatural and thick accent.
4.3 Affricate consonants
An affricate[ˈæfrɪkət] consonant begins as a stop and is released as a fricative. In English there are only two affricate sounds, [ʧ] and [ʤ].
4.3.1 Consonants [ʧ] and [ʤ]
Sound [ʧ] is voiceless and sound [ʤ] is voiced. Both are the combination of an alveolar stop and a post-alveolar fricative. The IPA symbols indicate the combination of the consonant sounds ([t]+[ʃ]=[ʧ] and [d]+[ʒ]=[ʤ]). In the case of the voiceless affricate [ʧ], stop [t] is less aspirated than [th]; the manner and place of articulation of the post-alveolar is exactly the same as in [ʃ]. This also applies to the voiced sound [ʤ]. Common spellings for [ʧ] are ch, t, and tch, as in choose/ʧu:z/, question[ˈkhwesʧən], or catch[khæʧ]. In the case of [ʤ], its most common spellings are j in initial position, as in job[ʤɑ:b]; letter g, as in general[ˈʤen ɹəl]; and combinations ge and dge, as in large[lɑ:ɻʤ] and fridge[fɹɪʤ].
The first pronunciation problem with the affricates is associated with stops [t] and [d]. They are pronounced by native Spanish speakers as dental stops [t̪ ] and [d̪] instead of their alveolar counterparts (see Figure 13, Section 4.1.2subsubsection). The second problem is the aspiration of stops, as discussed in Section 4.1.3subsubsection. Aspiration is not present in Spanish and therefore affricates sound weak or poorly enunciated to English ears. Third, since fricative [ʃ] does not exist in Spanish, it is often replaced by affricate [ʤ], which does exist in Spanish (not exactly the same). Finally, voiced affricate [ʤ], not present in Spanish, is often pronounced as voiceless [ʧ].
Another kind of problem found in native Spanish speakers is the pronunciation of affricate [ʧ] as semivowel [j], yielding juice rather than use (noun).
4.4 Nasal consonants
In this kind of consonants the air can escape freely from the nose because the soft palate does not lean against the rear wall of the throat but just hangs loosely. Therefore, the air passes through the oral and nasal cavities. Nasal consonants in English are [m], [n], and [ɳ]. However, these consonants are actually stops and during the closure and blockage stages the air only escapes from the nose.
4.4.1 Stops [m], [n], and [ɳ]
Consonant [m] is a bilabial stop, consonant [n] is alveolar stops, and consonant [ɳ] is a velar stop. They can be thought of as the nasal version of the oral consonants [b], [d] and [g], respectively. In Figure 33, the difference in terms of manner and place of articulation between sounds [m] and [p, b] can be observed. The soft palate is lowered allowing the air escape from the nose. These changes several features of the produced sound, as resonance, amplitude (it is lower than in stops or other consonants), and timbre.

|
Sound [m] is usually spelled m or mm, as in more[mɔ:ɻ] or comb[koʊm]. In the video below Rachel explains the pronunciation of this sound.
Apart from nasality, sound [n] is pronounced as [t] in terms of manner and place of articulation, that is, it is an alveolar stop. Sound [n] is usually spelled n, nn, or kn, as in not[nɑ:t], sunny[sʌni], or know[noʊ]. In the video below Rachel explains the pronunciation of this sound.
Last nasal sound is [ɳ], a velar stop like [k] and [g]. In Figure 36, phonemes [ɳ] and [k] are compared. In the case of [ɳ] the back of the tongue and the soft palate meet in such a way the nasal tract is not sealed off.

|
Sound [ɳ] is associated with some fixed spellings:
- The ending of the present participle ing, as in eating[ˈi:tɪɳ].
- Letter n before k, g pronounced as velar stops is pronounced as ɳ, as in think[ɵɪɳk], or angry/ˈæɳgɹi/. Therefore, spellings nk are ng frequently associated with this consonant.
Sound [ɳ] is not contrastive in Spanish and speakers often drop it in word-final position, making sing[sɪɳ] and sin[sɪn] sound the same.
4.5 Approximant Consonants
The definition of an approximant/əˈprɑ:ksɪmənt/ consonant is somehow delicate, as observed by several authors (see [LM96] and [MC04]). The sound is formed by the coming of two articulators close together, neither as much as creating frication nor as being treated as a vowel sound. Within the class of aproximants, three subclasses of sounds occurring in English can be distinguished:
- Central aproximants: The airstream is directed through the centre of the mouth by the tongue. Within this group, we find r-sounds such as alveolar approximant [ɹ], flap approximant [ɾ], retroflex approximant [ɻ] as well as semivowels [j] and [w].
- Lateral aproximants: The airstream is directed to the sides of the mouth by the tongue. The centre of the tongue (often the tip) actually touches the roof, but the approximation to the alveolar ridge is produced with the side of the tongue; hence, the term for its classification. Sounds [l] and [lɤ] are lateral approximants.
4.5.1 r-Consonants [ɹ], [ɾ], and [ɻ]
In English letter r can be pronounced in three different ways, namely, [ɹ], [ɾ], and [ɻ], the three being r-consonants. They are given that name because letter r is usually pronounced as one of these sounds. More technically, they are called rhotics/ˈroʊtɪks/; see, for example, [LM96].
Sound [ɹ] is an alveolar approximant, which means that the sound is produced by moving the tongue close to the alveolar ridge, but not as much as creating frication. Here there is a complete description of the tongue movements:
- The front of the tongue is first pulled back a little bit and then raised.
- More importantly, the back of the tongue is expanded so that it touches the bottom of the top teeth (near the molars) at both sides. This forms a central channel over which the airstream passes (sound [ɹ] is a central consonant).
- The blade and tip of the tongue are in neutral position without making contact with other parts of the mouth.
- The lips are somewhat rounded, more on word-initial positions, as in red[ɹed], and less in word-internal positions, as in camera[ˈkæməɹə] or stress[stɹes].
Note that the term approximant does not mean the tongue does not touch the roof of the mouth at all; it means that where the sound is produced, there is only approximation, but other parts of the tongue may touch the roof of the mouth, as it actually occurs in sound [ɹ]. The approximation in this case takes place at the central channel formed by the tongue. Within this sound there is great variation as the position of the tip is concerned. Some authors contend that the tongue is a little bit curved up rather than in a neutral position. For example, Roach [Roa09] (pages 49–50) speaks of the tip of the tongue “approaching the alveolar area in approximately the way it would for a [t] or [d], but never actually making contact with any part of the roof of the mouth”. Other authors observe that in general the tip and blade of the tongue may adopt the position of the previous sound, as it occurs in combination such as [tr] or [dr], as in train[tɹaɪn] or drain[dɹaɪn].
Sound [ɹ] appears at prevocalic positions in a syllable or syllable-clusters, as in red[ɹed], camera[ˈkhæməɹə], train[thɹeɪn], confrontation[ˈkhɑ:nfɹənˈtheɪʃn], or program[ˈphɹoʊgɹæm].
Rachel summarizes part of the above discussion in the video below.
The second r-consonant is the alveolar flap [ɾ]. This is an allophone of phonemes /r/ and /t/ and it only occurs in American English. The manner of articulation is essentially the same as in the sound [ɹ], except for the flap. As in [ɹ], the front of the tongue is pulled back and raised, but then the tip of the tongue makes a rapid movement upward and then downward, slightly touching the alveolar ridge. This movement is called a flap.
As an allophone of phoneme /r/, sound [ɾ] appears at intervocalic position when the stress of the word is carried by the first vowel, as in cereal[ˈsɪɾɪəl], or carol[ˈkæɾəl]. However, notice that at other positions this allophone is not pronounced, as in camera[ˈkæməɹə], because the vowel before letter r is not stressed. This alveolar flap also happens when words are linked together, as in Don’t jeer at him, which is pronounced [ˈdoʊntˈʤɪɾəthɪm].
Sound [ɾ] is also an allophone of phoneme /t/, perhaps one the most distinguishing pronunciation features in American English. Mainly, it substitutes allophones [th] or de-aspirated [t]. This change takes place when /t/ is at an intervocalic position when the first vowel is stressed, as in water/ˈwɔ:ɾəɻ/. This phenomenon also applies when words are linked together in a full prosodic unit, as in the sentence What is this?[ˈwʌɾɪzˈ∂ɪs].
In this video Rachel gives examples of the pronunciation of [ɾ].
The third r-consonant is the retroflex[ˈretrəfleks] approximant [ɻ], responsible for the so-called rhotic[ˈroʊtɪk] accent or r-coloring. The rhotic accent is one of the main differences in pronunciation between British and American English. For more information on the rhotic accent, see [Góm12a] and [Wik11] and the references therein. Sound [ɻ] is pronounced as follows:
- The retroflex approximant [ɻ] always occurs after a vowel sound. Below are described the precise circumstances where that takes place.
- Therefore, the initial position of the tongue is that of the preceding vowel.
- After the vowel is pronounced, the tongue takes a neutral position in the mouth both and the tip of the tongue is curled back towards the alveolar ridge to produce the sound [ɻ].
The rhotic accent can be found associated with the following sounds:
- Long vowels [ɑ:], [ɔ:], and [ɜ:], as in hard[hɑ:ɻd], borne[hɔ:ɻn], and hurt[hɜ:ɻt], respectively.
- After the short sound schwa [ə] in the comparative endings, as in later[ˈleɪtəɻ], or taller[ˈtɔ:ləɻ].
- A word-final vowel followed by [ɹ] is pronounced as vowel followed by [ɻ], as in here[[hɪɻ], and hair[heɻ].
- The combination [jʊ], as in cure[khjʊɻ], or pure[phjʊɻ].
- After the short sound [ʊ], as in poor[phʊɻ], moor[mʊɻ], or boor[bʊɻ].
Furthermore, rhotic accent is produced according to the following circumstances (here we have followed [Góm12a] and the references therein).
- There is rhotic accent when a word is pronounced in isolation or at the end of a prosodic break. For example, It was very hard[ɪtwʌzˈveɹihɑ:ɻ].
- The rhotic accent is lost when the letter r does not belong to the same syllable. Compare water[ˈwɔ:ɾəɻ] and watery[ˈwɔ:ɾəɹi].
- If within a prosodic unit the last syllable of a words ends by [ɻ] and the next word begins by a vowel, then the rhotic consonant is substituted by [ɹ] or [ɾ], depending on the particular accent. For example, the sentence That water is cold is pronounced as [∂ætˈwɔ:təɹɪzˈkoʊld]; notice the change from [ɻ] to [ɹ] in water. Also, it could be pronounced as [∂ætˈwɔ:təɾɪzˈkoʊld].
In the next video Rachel explains the pronunciation of [ɻ]
Common spellings associated with r-consonants are r, rr, and wr, as in run[ɹʌn], sorry[ˈsɑ: ɹi], and wrap[wɹæp˺], lyrics[ˈlɪɾɪks], parryl[ˈpæɾi], water[ˈwɔ:ɾəɻ], or hard[hɑ:ɻd].
Some native Spanish speaker experience difficulties when pronouncing sound [ɹ], specially in placing the tongue at the right position. Sometimes, Spanish trilled [r] is pronounced instead of the correct sound [ɹ].
Since the usage rules for the r-consonants are quite clear and complementary, most dictionaries transcribe the three [r]-sounds as simply [r] (even though, IPA symbol [r] is used to represent a coronal trill). In this article we have followed that transcription practice except for the description of allophones.
4.5.2 Lateral sounds [l] and [lɤ]
In lateral sounds, as already mentioned, the airstream is directed to the sides of the mouth owing to the action of the tongue. How does the tongue achieve that? The tongue possesses muscles that allows it to broaden and narrow its body; check again Figure 5. By narrowing its body and putting its sides down and in the tongue is able to achieve it. Both allophones [l] and [lɤ] are alveolar lateral approximants. The second sound is a velarized sound, but the first is not. Allophone [l] is pronounced as follows:
- The tip of tongue leans against the alveolar ridge.
- At this point, the sides of the tongue are down and in, forming two passages at each side. Compare the tongue positions for lateral and central consonants in Figure 41. The Figure shows a transverse cross-section of mouth as viewed from the front: on the left, it is a lateral consonant; on the right, it is a central consonant.
- The airstream comes from the lungs and passes through the lateral passages. Because this sound is voiced, the vocal cords are in vibration.
- The lips are in a neutral position, with the lips slightly rounded.

|
From this description, it follows that sound [l] is a voiced alveolar lateral approximant.
Allophone [lɤ] is a co-articulated consonant (see Section 4.1.5subsubsection), that is, the sound has two articulations. The first articulation is exactly the same as allophone [l]. The second articulation is a velarization[ˈvi:leraɪˈzeɪʃn]. While the tip of the tongue is resting on the alveolar ridge, the back of the tongue raises and come close to the soft palate (but without touching it). The velarization is indicated in IPA by adding the letter ɤ as a superscript to the first sound (symbol [ɫ] is also used). These two allophones [l] and [lɤ] are also known as light [l] and dark [l], respectively.
In theory, light [l] is pronounced before vowels, as in leaf[li:f], and dark l is pronounced in syllable-final positions, as in feel[fi:lɤ] or selfish[ˈselɤfɪʃ]. In practice, in American English most of the time only the dark [l] is heard, with the exception of formal speeches or some particular variants.
Phoneme /l/ is spelled l or ll, as in lot[lɑ:t], or tall[tɔ:lɤ]. In the video below Rachel explains both the light and dark l.
Most problems for native Spanish speakers arise from the pronunciation of [lɤ] as sound [l], which is not velarized in Spanish.
4.6 Semivowels
Semivowels are sounds that are articulated as vowels —they are not produced by creating a complete or partial obstruction in the upper vocal tract—, but function as consonants. Before going into the precise description of the semivowel sounds, we will elaborate further on the phonological features of semivowels in order to understand this apparent paradox. In English the structure of syllable consists of a initial consonant cluster, called onset (sometimes not present), followed by vocalic cluster (a single vowel, a diphthong or a triphthong, sometimes not present), followed by a final cluster called coda/ˈkoʊdə/ (sometimes not present). The vocalic cluster is called the nucleus/ˈnu:kliəs/ of the syllable4 (see [Roa09] for more information). The term consonant cluster here is quite generic and may refer to up to four consonants or none. Therefore, the general structure of the English syllable is (C)+V+(C), where C stands for consonant and V for vowel cluster. Here we have several examples with different consonant structures:
- V: awe[ɔ:], owe[oʊ]. Although rare, there are some words in English containing no consonants.
- C+V: Key[khi:], no[noʊ], lie[laɪ], true[thɹu:]. In these examples the coda is not present and the onset is composed of one consonant.
- V+C: Ease[i:z], ought[ɔ:t], ash[æʃ], aim[eɪm]. The onset is not present and again the consonants have only one sound.
- C+V+C (simple examples): Caught[kɔ:t], rain[raɪn], man[mæn], feel[fi:lɤ]. In these examples both the onset and coda are present in the syllable.
- C+V+C (complex examples): Play[phleɪ], ask[æsk], stop[stɑ:p], spray[spɹeɪ],
asks[æsks], fifths[fɪfɵs], strain[stɹeɪn], stops[stɑ:ps], straps[stɹæps],
strands[stɹændz], prompts[phɹɑ:mpts]. - Examples including semivowels:
- Semivowel+V: you[ju:], woe[woʊ], yes[jes].
- C+semivowel+V: few[fju:], phew[pju:], spew[spju:].
- Semivowel+V+C: year[jɪɻ], your[jɔ:ɻ], were[wɜ:ɻ], wore[wɔ:ɻ], one[wʌn],
what[wɑ:t]. - C+semivowel+V+C: pure[phjʊɻ], thwack[ɵwæk], cure[khjʊɻ], sweet[swi:t],
swear[sweɻ]. - In the middle of longer words: popular[ˈphɑ:pjələr], quietly[ˈkhwaɪtli],
beauty[ˈbju:ti], earthquake[ˈɜ:ɻɵkhweɪk], circular[ˈsɜ:ɻkjələɻ].
After having examined the examples above, we conclude that semivowels in English are never part of the nucleus of a syllable. Hence, they act as consonants. However, as we will see next in detail, they behave as vowels in terms of articulation. The following is a list of the main features of semivowels:
- Glides: Semivowels are always glides, that is, continuous transitions between two sounds, where the first sound is always the semivowel. The target sound is the second sound; the semivowel is a very short sound. See, for example, you[ju:], sweet]swi:t˺], or your[jɔ:ɻ].
- Consonant boundaries: In all the examples listed above the semivowel appear as the last sound of the onset. Semivowels are never encountered in the middle of a consonant cluster or in the coda.
- Differences with diphthongs: Semivowels are not diphthongs. While in diphthongs the main sound is the first, in semivowels the main sound is the second; compare the following pairs diphthong-semivowel [aʊ]-[jʊ], [ɪə]-[jə], or [ɔɪ]-[wɔ:]. While diphthongs always functions as vowels and belong to the nuclei of syllables, semivowels never do.
4.6.1 Palatal semivowel [j]
This semivowel is pronounced in a similar way to vowel [i:], but semivowel [j] is very short. Another difference is that in the case of vowel [i:] the tongue does not touch the roof of the mouth, while in the case of semivowel [j] contact is made. In the articulation of [j] the front of the tongue is raised and then the sides of the tongue touch the hard palate. A groove in the middle of the tongue is formed over which the sound travels. The tip of the tongue are down, just behind the bottom front teeth. Notice that [j] is a central consonant as the air is directed through the centre of the mouth.
Sound [j] is usually spelled y, as in year[jɪr].
Semivowel [j] is sometimes replaced by palatal lateral approximant [ʎ] by native Spanish speakers. This also happens with affricate [ʤ]. In English [j] be haves as a consonant found at the boundary of the onset, whereas in Spanish it is considered as part of a diphthong. This might explain the difficulties in properly pronouncing this sound. Not only does the phonetic description of a sound matter to its pronunciation, but also its distribution and function.
4.6.2 Velar semivowel [w]
Semivowel is another co-articulated sound. It is articulated as a voiced approximant at the velum and at the same time is articulated with the lips. More precisely, this sound is termed as a labio-velar approximant[ˈleɪbioʊˈvi:lər] . The articulation of [w] is carried out as follows:
- The lips are projected forward and take on a rounded position.
- The back of the tongue is pulled back and raised and comes close to the soft palate. This position is similar to that of vowel [u:], but the back of the tongue is closer to the soft palate.
- The vocal cords then vibrate and the lips are retracted to the position of the next sound in the word.
- Because the tongue has to move up towards the soft palate, the root of the tongue also moves and narrows a little bit the pharynx. This gives the sound a characteristic timbre.
Sound [w] is usually spelled w or wh, as in way[weɪ], or where[weɻ]. In the video below Rachel explains the production of this sound and gives examples.
There is an equivalent sound to [w] in Spanish, but it is not as labialized as in English. Furthermore, [w] in English appears in non-existing combinations in Spanish, as in would[wʊd], where [w] is followed by [ʊ]. Some native Spanish speakers may pronounce would as [gud].
5 Further material on consonants
In this Section we will cover a few topics that were left out either because the material would otherwise be lengthy, or because discussions would be too technical for the intended reader at that moment, or because of expository reasons. In particular, we favour the idea of presenting consonants in detail and at the end show a general, encompassing classification.
5.1 Other pronunciation problems of Spanish language
Throughout this article we showed the reader the main pronunciation problems associated with each English consonant that native Spanish speakers may be confronted with. However, there are a couple of pronunciation problems not associated to any consonant in particular and that are still worth mentioning:
- Final consonant clusters. English has a larger and more diverse inventory of consonant clusters than Spanish does. English may have up to four consonants in a row in word-initial or up to three in word-final, as in texts[teksts], asks[æsks], felt[felt], stress[stres], skunk[skʌɳ]. This consonant complexity, along with an imprecise manner of articulation, specially in phonemes /s/ and /t/, make the pronunciation of many native Spanish speakers obscure.
- [d]versus [∂]. Phoneme [d] is realized in Spanish as a dental stop [d̪] or a dental fricative ∂. The latter is always pronounced when letter d is between two vowels; the former, in the remaining cases. In other words, letter d changes its pronunciation depending on its position; it is a positional variant in Spanish. Native Spanish speakers not aware of this situation tend to apply this rule to English pronunciation. The result is that word this is mispronounced [dɪs] (or even worse, [d̪ɪs]) instead of the correct version [∂ɪs].
- [b] versus [ʱ]. In Spanish letter b at intervocalic position is pronounced as a bilabial fricative [ʱ]. If not explained properly, a native Spanish speaker may pronounce lobby as [ˈlɑ:ʱi] instead of [ˈlɑ:bi]. Most Spaniards could not tell the difference between [b] and [ʱ].
5.2 Syllabic consonants
In Section 4.6subsection we described the structure of the English consonant as (C)+V+(C), where C stands for consonant cluster, V for vocalic cluster, and parenthesis are used to indicate optional elements. However, that description, strictly speaking, was not complete. In English it may happen that a syllable is composed of no vocalic cluster; of course, in that case something else must be part of the syllable. Syllabic consonants are consonants that form a syllable on its own. Syllabic consonants are never stressed and are always voiced. When a consonant acts as a syllable, it is marked by a central subscript, as in l ˈ or m ˈ ; this is the IPA diacritic to denote syllabic consonants. In English syllabic consonants are [n], [m], and [l]. For example, the following words have syllabic consonants: seven[ˈsevn ˈ ], awful[ˈɔ:fl ˈɤ], rhythm[ˈɹɪ∂m ˈ ]. Unaware students may pronounce these words by inserting a schwa in between the two consonants to form a syllable with vocalic nucleus, as in even[ˈi:vən], but that would still be incorrectly pronounced.
5.3 Classification of consonants
We have deferred a classification of consonants until the end of this article because we believe that presenting a complete classification to the student at beginning would be to some degree misleading. The student at that stage would not possess the knowledge and experience to understand what that classification is for. Such a categorization should be given much later, and that is the reason to introduce it at the end.
A consonant was defined as a sound produced by a partial or complete obstruction of the airstream (see Section 3.2subsection). That definition, which refers to manner of articulation, can be refined by splitting the group of consonants into two broad categories, obstruents[əbˈstru:ənts] and sonorants[ˈsɑ:nərənts]. Actually, this classification is based on the degree of stricture[ˈstrɪktʃər], how narrow the gap is between the active articulator and the passive articulator at the narrowest point in the vocal tract [Col12]. The degree of stricture can be complete, with a complete blockage of the airstream, as in stops; complete approximation, with partial blockage resulting in frication, as in fricatives; and open approximation, with no frication, as in approximants and vowels. See [Man12] for more details on stricture. In obstruents, the sound is either stopped or interfered with in the vocal tract. Obstruents are stops, fricatives, and affricates. In Figure 45 a complete classification of obstruents is given (sounds in the boxes are sibilant consonants; sounds to left to the bullet are voiced and to the right voiceless).

A sonorant is a consonant produced in a continuous manner, as opposed to stops, and without turbulence in the airstream. All sonorants in English are voiced (and in most of world’s languages). In Figure 46 the classification of sonorants is shown.

The two previous classifications provide a good example to illustrate the difference between phonology and phonetic features. A phoneme is an abstraction of sound features through which speakers and listeners extract meaning. A phoneme has a set of allophones associated; for example, phoneme /p/ has [ph], [p=], and [p˺] as its allophones. In Figures 45 and 46 the phonemic features are on the top and as we go down, the phonetic features start appearing.
6 Further material
6.1 Diaphragmatic breathing
Learning how to pronounce a second language may result in more demands on your voice. It is fundamental to be able how to do diaphragmatic breathing. The diaphragm is a thick, umbrella-shaped muscle located below the lungs. During inhalation the diaphragm opens up and enlarges the thoracic cavity, drawing the air into the lungs. See a clear illustration of how the diaphragm works at the website Voice and Speech Source If diaphragm is used fully and efficiently, we will be able to talk for longer and, which is more important, in a more relaxed way. Learning how to do diaphragmatic breathing can be achieved through a well-chosen set of exercises. Check out the website Speech Therapy Information and Resources for reliable information.
6.2 Speech articulators
The website SPAN, the Speech Production and Articulation Knowledge Group at the University of Southern California, has a list of very instructive videos where we can watch the vocal tract of a young lady while she talks. Magnetic resonance technology has been used to highlight all main articulators, lips, jaw, tongue, soft palate; place and manner of articulation can be observed as her speech progresses. The best videos are Spontaneous speech, and Automatic contours (the contour of the tongue and the roof of the mouth). We strongly recommend the reader to watch them.
6.3 Tongue shapes
Epstein and Stone [ES12] define four categories for tongue shapes that are relevant to speech sound production: back raising, front raising, continuous groove, and two-point displacement. In Figure 47 the four tongue shapes are depicted. Back raising appears in vowels such as [ʌ] or [ʊ]. Front raising occur in sounds as [i:] or [ʃ]; notice that these two sounds require a close approximation to the hard palate. Continuous groove is typical of sibilants, as already established, but also appears in vowel soudns, as in [æ]. Finally, two-point displacement is associated to lateral sounds, as [l]; in the Figure below we can notice the points where the tongue makes contact with the hard palate and how the sides of the tongue are put down and in. If we compare the groove created in [ʃ] with the one created in [s], we will realize that in the latter case is deeper and longer. Therefore, in the case of [s] the jet of air seems is channel into the teeth at a high speed, which may explain the characteristic hissing sound of this consonant. Visualizing these tongue shapes may be of great help to the student of English.

Other authors have given alternative classification of tongue shapes; see [Wik12c]. For example, among English sibilants, two tongue shapes are worth mentioning.
- Grooved tongue shapes: They appear in sibilants sounds such as alveolar fricatives [s] and [z]. The groove runs down the medial axis of the tongue and tends to be deep and long. In general, these tongue shapes correspond to high-pitched, piercing sounds.
- Palato-alveolar tongue shapes: They occur in post-alveolar sounds such as [ʃ] and [ʒ]). The tongue is “domed”, that is, it adopts a convex and moderately palatalized position.
I exhort pronunciation teachers to include these kind of information in their courses, specially in advanced ones. The more exact and vivid the description of a sound is, the better and the faster it will be learnt.
References
[AE92] Peter Avery and Susan Ehrlich. Teaching American English Pronunciation. Oxford Handbooks for Language Teachers Series. Oxford University Press, 1992.
[Ass] The International Phonetic Association. IPA Chart. http://www.langsci.ucl.ac.uk/ipa/ipachart.html.
[Bal12] Rodney Ball. Introduction to phonetics for students of English, French, German and Spanish. www.llas.ac.uk/resources/mb/296, accessed in 2012.
[Bre12] David Brett. English phonetics and phonology. http://davidbrett.uniss.it/, accessed in 2012.
[Chr52] P. Christopherson. The glottal stop in English. English Studies, 33:156–163, 1952.
[CM08] B. S. Collins and I. M. Mees. Practical Phonetics and Phonology: A Resource Book for Students. Routledge English Language Introductions, 2008.
[Col12] J. Colleman. Phonetics course handouts and online resources. http://www.phon.ox.ac.uk/jcoleman/undergraduate˙course˙index˙mt06.html, accessed in 2012.
[DN69] N. Davidsen Nielsen. English stops after initial /s/. English Studies, 50:321–339, 1969.
[Eng12] Rachel’s English. Rachel’s English videos - Sounds. http://www.rachelsenglish.com/videos/sounds, accessed in 2012.
[ES12] M. A. Epstein and M. Stone. Shape categories and tongue motion in English stop. www.speech.umaryland.edu/Publications/ASA˙4psc39.pdf, accessed in 2012.
[Gie92] H. J. Giegerich. English Phonology. Cambridge University Press, 1992.
[Góm12a] Paco Gómez. British and American English pronunciation differences. 2012.
[Góm12b] Paco Gómez. Pronunciation of American English Vowels. 2012.
[Hay08] B. Hayes. Introductory Phonology. Wiley-Blackwell, 2008.
[Hig] J. Higgins. Minimal pairs for English RP. http://myweb.tiscali.co.uk/wordscape/wordlist/.
[HP03] K. M. Hiiemae and J. B. Palmer. Tongue Movements in Feeding and Speech. Critical Reviews in Oral Biology and Medicine, 14:413–429, 2003.
[Jen12] Jennifer. English with Jennifer. http://www.englishwithjennifer.com/, accessed in 2012.
[LM96] P. Ladefoged and I. Maddieson. The Sounds of the World’s Languages . Wiley-Blackwell, 1996.
[LM05] P. Ladefoged and I. Maddieson. Vowels and Consonants. Blackwell, 2005.
[Man12] R. Mannell. Phonetics and phonology - stricture. http://clas.mq.edu.au/phonetics/phonetics/consonants/stricture.html, accessed in 2012.
[MC04] Eugenio Martínez-Celdrán. Problems in the classification of approximants. Journal of the International Phonetic Association, 34(2):201–210, 2004.
[Mot11] B. Mott. English phonetics and phonology for Spanish speakers. Universidad de Barcelona, 2011.
[ODK97] W. O’Grady, M. Dobrovolsky, and F. Katamba. Contemporary linguistics. An introduction. Longman, 1997.
[PBL+06] I. Plag, M. Braun, S. Lappe, M. Schramm, W. Labov, S. Ash, and C. Boberg. Introduction to English Linguistics. Mouton de Gruyter, 2006.
[Roa09] Peter Roach. English Phonetics and Phonology. Cambridge University Press, 2009.
[Sev12] Several authors (List of authors). World atlas of language structures online. http://wals.info/, accessed in 2012.
[SL96] M. Stone and M. Lundberg. Three-dimensional tongue surface shapes of english consonants and vowels. Journal of the Acoustic. Soc. Am., 99(6):3728–3737, 1996.
[Wel90] John C. Wells. Syllabification and allophony. Routledge, 1990.
[Wel12] J. Wells. John Well’s phonetic blog. http://www.phon.ucl.ac.uk/home/wells/, accessed in 2012.
[Wik] Wikipedia. International Phonetic Alphabet. http://en.wikipedia.org/wiki/International˙Phonetic˙Alphabet. Accessed in November, 2012.
[Wik11] Wikipedia. American and British English pronunciation differences. http://en.wikipedia.org/wiki/American˙and˙British˙English˙pronunciation˙differences, accessed in 2011.
[Wik12a] Wikipedia. Aspirated consonants. http://en.wikipedia.org/wiki/Aspirated˙consonant, accessed in 2012.
[Wik12b] Wikipedia. Glottal stop. http://en.wikipedia.org/wiki/Glottal˙stop, accessed in 2012.
[Wik12c] Wikipedia. Tongue shapes. http://en.wikipedia.org/wiki/Tongue˙shape, accessed in 2012.
[Wik12d] Wikipedia. Voiced onset time. http://en.wikipedia.org/wiki/Voice˙onset˙time, accessed in 2012.
[Yav07] M. Yavas̞ . Factors Influencing the VOT of English Long Lag Stops and Interlanguage Phonology. In New Sounds 2007: Proceedings of the Fifth International Symposium on the Acquisition of Second Language Speech. Federal University of Santa Catarina Florianópolis, Brasil, 2007.
